til
大規模事前学習モデル
ページの構成の際、次の情報源を参考にした。
大規模事前学習モデルの学習手法
転移学習
深層学習モデルが学習を通じてデータの表現とタスク固有の学習を行っていることに着目し、すでに学習済みのモデルの重みを用いて新たなタスクの学習を行うこと。
| 学習の分類 | 目的 | 手段 | 例 |
|---|---|---|---|
| 事前学習 | より良い表現を得る | 自己教師あり学習が多い? | |
| 継続事前学習 | より良い表現を得る | 自己教師あり学習が多い? | 日本語コーパスでLLMなど |
| ファインチューニング | 個別のタスク特化する | 教師あり学習? |
事前学習が教師あり学習の場合は、汎用的な表現を得ることそのものが学習目的ではないため、例えば牧草が写っていたら牛と分類してしまうようなショートカット学習が行われることがあり、これがファインチューニングの妨げになる。
自己教師あり学習
ネットワーク構造の工夫より大量のデータを用意することでモデルの性能が向上すること、また転移学習により汎用的なモデルが固有タスクにおいても性能を発揮することを背景として、大量のラベル無しデータから学習する方法が模索された。
あらかじめ存在する事実のデータから、学習のためのデータを自分で作成する手法が自己教師あり学習である。例えば、テキストの一部をマスクしてその単語を当てるとか、画像を加工した上で、加工前後の画像を見比べて同じであれば高い報酬を与えるなどである。
具体的な手法については、Masked Language Modeling、対比学習を参照すること。なお、自己教師あり学習は、BERTの論文では教師なし事前学習とも呼ばれていた。
評価の方法としては、ラベル付き分類データを用いて埋め込みを取得し(全結合層で変換する手前の値)、k近傍法を用いるもの、シンプルに下流タスク用のヘッドを取り付けて性能を測るもの、下流タスクのための層を加えてフルパラメータのファインチューニングを行うものなどがある。
自己教師あり学習のデータ
LLaMAの学習に用いられたデータはWebからクロールしたデータで、CommonCrawlを初めとした4TB以上のサイズを持つ。また、GPT-3の事前学習トークン数は4100億, GPT-4は13兆トークンと言われる。
[!NOTE] データの質を上げて量を絞ると、訓練にかかるコストも削減できるの? 調査中…
[!NOTE] Webからクロールしたデータはゴミも多い。データの質に着目した量の指標はないの? 調査中…
データの前処理パイプラインは次の通り。ただしデータセットによって前処理の仕組みは異なる。
- Quality Filtering
- De-dup (重複排除)
- Privacy Reduction
- Tokenization
自己教師あり学習の訓練
次のトークンの生成確率をひたすら予測する。数理的には、トークンの生成確率から交差エントロピーを算出し、そのミニバッチ内での平均をLossとする。
Next Token Predictionでは、一般的に1epochのみ学習させる。
対比学習(対照学習)
事前学習としての表現学習に用いられる手段の一つ。エンコーダとしての多層ニューラルネットワークと射影ヘッドからなるモデルに対して、ミニバッチで複数のデータ拡張された画像を与える。
対比学習の手法の1つ、SimCLRではInfoNCE損失関数(Desmos[🔐])を用いる。 ミニバッチ内の同じ画像のデータ拡張から得たベクトルのコサイン類似度は近くなるように、そうでないベクトルのコサイン類似度は遠くなるように学習を進める。(正例のコサイン類似度/負例のコサイン類似度合計)にマイナスを付けて損失にするが、exponentialを取ってから自然対数を取り直す一工夫が入っている(正例・負例の部分を逆数にした方が、マイナスが取れて式がシンプルでは?)
継続事前学習
継続事前学習においても前処理のパイプラインがある。Swallow[^swallow_2023]コーパス![^swallow-corpus_2023]のパイプラインは次の通り。  
- 日本語のテキスト抽出
- 品質フィルタリング (3兆文字 → 1兆文字)
- 文字数が400文字以上である
- 日本語の文字数が50%以上である, 他
- 重複フィルタリング (1兆文字 → 3500億文字)
- ホスト名フィルタリング (3500億文字 → 3100億文字)
継続事前学習はドメイン特化LLMの開発にも用いられる。ドメイン特化には継続事前学習, SFT, RAGなどの手法が考えられる。
知識を参照するだけならRAGの方が性能が良い一方で、論理的思考など知識を活用するには継続事前学習の方が有利という主張がある。[^pfn_2024] [^pfn_2024]: https://tech.preferred.jp/ja/blog/llm_knowledge_injection/
ドメイン特化のための継続事前学習の工夫としては、生のテキストデータではなく、テキストの読解力を問う問題に加工して与えるなどの工夫がある。
語彙拡張
スケール則
計算資源、データセットサイズ、パラメータ数を適切に引き上げることで、モデルの性能を向上させる(=誤差を減らす)ことができる。これらの値には、次の関係が成り立つことが経験的に知られている。
\[\begin{align} L(X) = (\frac{X_c}{X})^\alpha \end{align}\]ただし、$L(X)$は誤差、$X$は計算資源, データセットサイズ, パラメータ数のいずれか、$\alpha$は$L(X)$と$X$の両対数グラフの負の傾きを表す。
スケール則を用いることで、与えられた条件内で到達できる最小の誤差を予測することができる。また、スケール則は深層学習のタスクの種類(翻訳, 画像分類, 音声認識, etc…)を問わずに発現することが報告されている。[^Hestness_et_al_2017] [^Hestness_et_al_2017]: J. Hestness et al., “Deep Learning Scaling is Predictable, Empirically,” arXiv.org. Accessed: Oct. 02, 2024. [Online]. Available: https://arxiv.org/abs/1712.00409v1
計算量の単位としてはFLOPs (Floating Point Operations, 浮動小数点演算性能)、またはPF-daysが用いられる。PF-daysとは、1Peta FLOPS(Floating points operation per second, 末尾Sが大文字であることに注意)の処理性能を持つサーバーを何日分計算に使ったかを示す量である。
また、スケール則を用いることで、計算資源に対して最適なモデルのパラメータ数とトークン数を求めることができる。Chinchilla論文では、パラメータ数:トークン数=1:20の比通が良いとされる。
Fine-Tuning
LLMの訓練フローは、次の3ステップからなる。
- Pre-Training (事前学習)
- Supervised Fine-Tuning
- Reinforcement Learning from Human Feedback (RLHF)
事前学習以降は広義のFine-Tuningなので、RLHFと区別する意味でSupervised Fine-Tuningと呼ばれる。
Instruction Tuning
Fine-Tuningの中でも、指示・回答の形式に統一したデータセットで言語モデルをFine−Tuningする手法をInstruction Tuningという。主にタスクへの適応を行っている一方で、新たに知識を獲得するのではなく事前学習で得た知識を引き出すことで改善を実現している、という説がある。
Instruction TuningされたモデルはZero-shot性能が向上する。つまり、特定の応答を超えた汎用的な指示の理解能力を得ると考えられる。
派生手法としてIn-Context TuningやSymbol Tuningが存在する。In-Context Tuningでは、単なる応答を超えて例を含む応答で訓練することで、Few-shot性能を向上させる。Symbol Tuningでは、正しい答えが質問に含まれる場合に、それらを無関係なシンボル(barなど)に置き換えて訓練する。
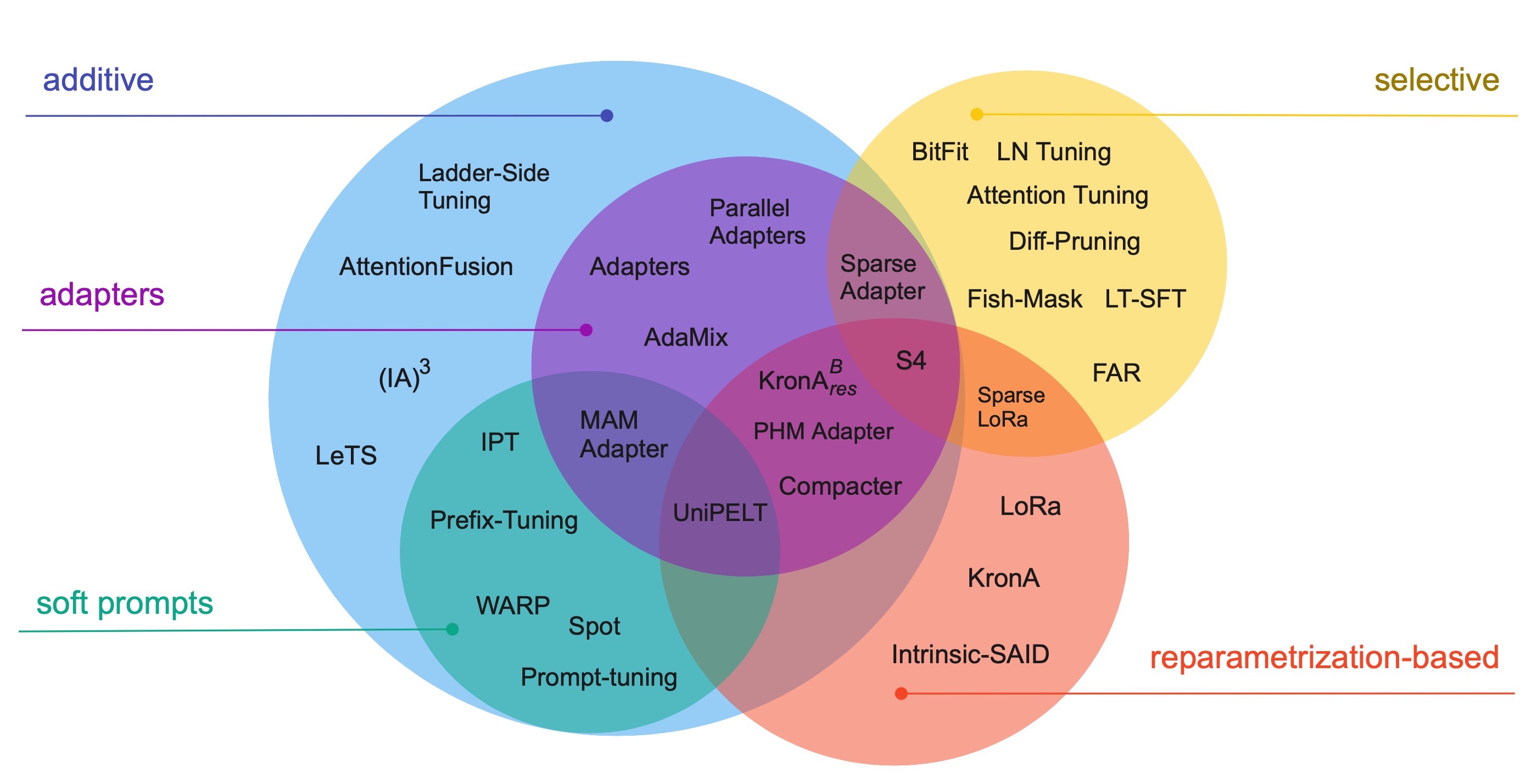
Parameter Efficient Fine-Tuning
大規模なモデルに対してFine-Tuningを行うと、莫大な計算リソースが必要になる。そこで、一部のパラメータや追加したパラメータのみを対象にしたパラメータ効率の良いFine-Tuningが考えられる。これをParameter Efficient Fine-Tuning (PEFT)という。
PEFTの代表的な手法としては、次の4つが存在する。
| Name | Description | Pros | Cons |
|---|---|---|---|
| Adapters | Transformer内にモジュールを追加 | 訓練パラメータ数が小さい | 推論にオーバーヘッド |
| Soft Prompts | モデルは変化させず、タスクのためのプロンプトをベクトル形式で学習 | モデル学習不要, 性能高い | 入力のContextを圧迫 |
| Selective | 各モジュールのバイアス項だけを学習 | 学習データ数が小さい領域ではFull-FTより高精度 | 大規模モデルではFull-FTに対して精度が劣る |
| Reparametrization-based | Full-FT後の重み - 現在の重みの差分のみを学習 | タスク依存だがFull-FTと同等の精度 | タスクに寄ってはFull-FTと比較して著しい性能の劣化 |
RLHF & Alignment
LLMの訓練にあたって、教師あり学習では文法や知識、応答の形式を学習させることが可能である。しかし、教師あり学習では善悪など人間の意図に沿った回答を学習させるのは難しいとされている。そこで、人間をフィードバックサイクルに含む強化学習で意図を学習することが効果的である。そのような意図を学ばせる調整をAlignmentといい、学習をRLHF (Reinforcement Learning from Human Feedback)と言う。
Alignmentの基準としてはHelpful, Honest, Harmlessなどがあり、これらをまとめてHHHと呼ぶ論文もある。関連して、次のようなデータセットがある。
- ThoughtfulQA: LLMの真実性や難しい知識に対する能力を測るデータセット
- HalEval: ハルシネーションの少なさを測るデータセット
- SHP(Stanford Human Preferences Dataset): Redditを元に作成した、よりHelpfulな回答が高いスコアを持つと想定したデータセット
- HH-RLHF: HelpfulとHarmlessの2軸で評価したデータセット
RLHFについて、特にChatGPTの前進であるInstructGPTでは、次の手順で学習が行われた。
- 強化学習の報酬を与えるモデルの最初の訓練データを生成するモデルを、プロンプト-人間の回答から教師あり学習によって訓練する
- 強化学習の報酬を与えるモデルを訓練する。プロンプトに対して複数の出力を行い、それらを人間がランク付けし、それによって訓練する
- 報酬モデルからPPOによって強化学習を行う
RLHFのように、学習サイクルに人間が加わることをHuman-in-the-Loop機械学習という。広義には機械学習の訓練・運用のプロセスに人間が参加することを言うようだ。[^itmedia_2022]狭義には、継続的に能動学習を行うことで人間の知見を取り込むことを指すようにみえる。 [^itmedia_2022]: ヒューマン・イン・ザ・ループ(HITL :Human-in-the-Loop)とは?
また、Step2をルールに従ってAIが行う方法をRLAIFと呼び、Claudeなどで採用されている。[^anthoropic_2023] [^anthoropic_2023]: Claude’s Constitution
一方で、強化学習には問題点もある。報酬を最大化することを目的にしたモデルが望ましくない方策を学習する現象をReward Hackingという。また、汎化性能が劣化してしまう現象をAlignment Taxという。
DPO
能動学習
データの量が多い、専門性が高い等の理由からラベル付けのコストが高く付きそうな場合、学ぶデータに優先順位を付けるのが有向になる。アルゴリズムで新たに学習するデータを選ぶ手法を能動学習と呼ぶ。新たに学習するデータとしては、分類に迷うデータを選んだり、出現率が高いデータを選択する。
大規模事前学習モデルのスケール
大規模事前学習のスケールでは、パラメータ数・計算量・データが課題となる。Transformerでは、各単語が他のすべての単語との関連性を計算するため、系列長nの2乗の計算量とメモリが必要となる。また、良質なWeb上のデータが2024年頃に枯渇することが予想されている。
Efficient Attention
効率的なAttention機構全般を指す。Attentionを近似するアプローチとメモリアクセスに関する改善がある。
Attentionを近似するアプローチとしては、SparseなAttentionや低ランク近似によるAttentionの効率化がある。また、メモリアクセスに関する改善としてはFlash Attentionなどの取り組みがある。
量子化
モデルパラメータのデータタイプを浮動小数点から整数に変換して演算処理を行うこと。
Knowledge Distillation
大規模事前学習モデルのアーキテクチャ
BERT
拡散モデル (Diffusion Model) (2015)
推論時に指示を与える方法としてCFG (Cllasifier Free Guidance)があり、拡散モデル以外でも用いられている。
DDPM (2020)
潜在拡散モデル (Latent Diffusion Model, LDM) (2022)
- arXiv
- Applications
- Stable Diffusion
- Stable Diffusion XL
IP Adapter (2023-08)
Image Promptを入力するためのアダプター。
Diffusion Transformers / DiTs (2023)
拡散モデルのネットワーク部分をCNNベースのU-NetからTransformerで実装しようという試み。
特定のブロックをスキップしてCFGを与えるSLGという手法がある。
TeaCache (2024)
DiTを用いた動画生成モデルにおいて、推論時に出力の差が小さいタイムステップの出力のキャッシュを利用することで、推論結果に与える影響が小さい状態で1.5~2倍程度の高速化を行える技術。
dLLMs (2025)
- Implementations
拡散言語モデル。Transformerに比べて高速に推論ができるとされる。
FramePack (2025)
動画生成モデル。Wan VideoやHunyuan Videoがフレーム全体をまとめて生成するのに対して、FramePackはフレームを逐次生成するためVRAM消費量が少ない。
Frameを重要度合いに応じて圧縮するため Frame Pack という命名と思われる。
Transformer (2017)
Transformer[^vaswani_2017]は単語間の長距離依存性を把握できるようになったニューラルネットワークである。具体的には、全単語間にAttention機構を導入したRNNである。 [^vaswani_2017]: A. Vaswani et al., “Attention is All you Need,” in Advances in Neural Information Processing Systems, Curran Associates, Inc., 2017. Accessed: Jan. 05, 2024. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
TransformerがEncoder-Decoderブロックから構成される一方で、GPTはDecoderブロックからのみ構成される。Transformerが翻訳タスク向けに設計されたことが関係している。
Transformerでは単語の位置情報を知るため、位置埋込 (PE, Positional Encoding)を行う。単に位置インデックスを用いずに、トークンごとに計算したべクトル次元数分の波を用いることで、モデルが位置関係をより連続的に理解できる。
- Self-Attention
- Encoder/Decoder
- Multi-head attention
- Cross-Attention
- 残差結合
- 層正規化
Transformerは、様々な注意表現を学習するために異なるAttentionを何度も適用している。その結果、CNNのように同じフィルタを繰り返し適用するモデルと比較して、計算量やパラメータが多くなり、それらをメモリから読み出す頻度が上がった。
CPUの演算性能だけでなく、メモリI/Oを含めた性能を評価するためのモデルとしてルーフラインモデルがある。マシンの達成可能なFLOPSを計算するに当たり、CPUのピーク演算性能とメモリ帯域によって成約される性能の小さい方を取るもので、チャートが屋根のような形になることからそう呼ぶ。

ViT
BitNet (2024)
Attention Free Transformer (AFT) (2021)
Self-Attentionに依存しないアーキテクチャの一つ。代わりに全結合層を用いている。
RWKV (Receptance Weighted Key Value)
Self−Attentionに依存しないアーキテクチャの一つ。AFTに大きな影響を受けている。RNNのように再帰的で低コストな推論が可能であり、かつTransformerのように並列で学習可能である。
RetNet (Retentive Network)
Retentive: 保持力のある。RWKVと同様に並列に学習し、再帰的な推論が可能なネットワーク。スケーリングカーブ (モデルサイズ向上時の性能の引き上げ度合い)でTransformerを上回る。
S4
Mamba
CLIP (2021)1
大規模事前学習による画像言語モデル。画像・キャプションのペアを用いた対比学習による自己教師あり学習を行う。損失関数は次の通り(式の出典はCyCLIP2)
\[\mathcal{L}_{\text{CLIP}} = -\frac{1}{2N} \sum_{j=1}^N \log \left[ \frac{\exp \left( \left\langle I^e_j, T^e_j \right\rangle / \tau \right)}{\sum_{k=1}^N \exp \left( \left\langle I^e_j, T^e_k \right\rangle / \tau \right)} \right] -\frac{1}{2N} \sum_{k=1}^N \log \left[ \frac{\exp \left( \left\langle I^e_k, T^e_k \right\rangle / \tau \right)}{\sum_{j=1}^N \exp \left( \left\langle I^e_j, T^e_k \right\rangle / \tau \right)} \right]\]CyCLIP (2022)2
CLIPは正例と近い負例・遠い負例の距離に注意を払っていないため、画像をプロンプトで分類した場合と正解ラベル付き画像を用いてk-近傍法で分類した場合で結果に差が出ることがある。
次の考え方に基づいて損失を調整することで、精度を改善することができる。具体的にはそれぞれの距離の差の二乗を損失に加えている。
- 画像jとキャプションkの距離感は、画像kとキャプションjの距離感と同じであるべき
- 画像jと画像kの距離感は、キャプションjとキャプションkの距離感と同じであるべき
PAINT (2022)3
ファインチューニングによって汎化性能を失う問題に対して、ファインチューン前後の重みを線形補間した重みを用いることを提案している。これによって汎化性能と固有タスクを解く能力をある程度良いところ取りできるらしい。感想だが、ファインチューニングだけでは過学習が起きてしまう、ということを示唆しているように思える。
大規模事前学習モデルの推論
Prompting
LLMに少数の例を与えると性能が上がる。これをIn Context Learning (ICL)という。ICLはPromptingの一種と考えられる。
代表的なPromptのテクニックは次の通り。
- CoT (Chain of Thought) (ステップバイステップで考える)
- Few-shot learning (例示する)
LLMを提供している企業のプロンプトは次の通り。
ICL (In Context Learning, 文脈内学習)
事前学習・追加学習・推論の各段階で、文脈内学習の能力を上げるための工夫が考えられる。
RAG (Retrieval-Augmented Generation)
外部知識を利用したテキストの生成をRAGと呼ぶ。そのうち、関連する知識(文書)を取得する機能をRetrieverと呼ぶ。関連度合いの求め方によって、次のように分類される。
- Sparse Retriever
- キーワード検索
- TF-IDF
- 埋め込みのコサイン類似度
- Neural Retriever (Dense Retriever)
また、初めにキーワード検索を行い、次にNeural Retrieverを用いるようなRetrieverも考えられる。これをRerankと呼ぶ。
検索した文書の使い方は次の通り。
- コンテキストとして追加する (REPLUG)
- 複数の予測のうち、得られた文書から見て尤もらしい予測を採用する (KNN-prompt)
Tool Augmented Language model
プログラミング言語実行環境や電卓などを利用する言語モデルをTool Augmented Language Modelといい、代表的なモデルにGorillaがある。
推論時のスケーリング
同じモデルを使う場合でも、推論時に工夫をすることで性能を引き上げることができる。次の通り、様々なレベルの工夫が考えられる。
- Decodingによる工夫
- Greedy Decoding
- Beam Search
- Random Sampling
- Promptingによる工夫
- メタ生成 (Meta-generation)アルゴリズムによる工夫
- Parallel Search
- Step level search
- Refinement
大規模事前学習モデルの評価
ツールが公開されているほか、リーダーボードが公開されている。
- Open LLM Leaderboard 2 (Open LLMのリーダーボード, 1からタスクを刷新)
- Nejumiリーダーボード (日本語に特化)
LLM
LLMにおけるハルシネーションについて、検出と評価のためのベンチマークが提案されている。次の通り。
- HaluEval
- 会話のデータをLLMに見せたあと、その会話がハルシネーションを含むか否かをYes/Noで回答させるデータセット
- Truthful QA
- Jtruthful QA
- REALTIME QA
画像認識モデル
画像認識モデルの表現学習の手法としては自己教師あり学習がよく用いられる。それに対して、評価手法としては下流タスクの性能を測ることが一般的である。下流タスクの例は次の通り。
- 画像分類
- 物体検出
- 意味的領域分割
- インスタンス領域分割
VLM
画像言語モデルの性能を測るには、様々な下流タスクの精度を用いることが一般的である。それに加えて、下流タスクの精度の改善のためにモデルの特性を測るためのベンチマークがいくつか提案されている。例えば、VL-Checklist (2023)[^zhao_2023]が上げられる。 [^zhao_2023]: T. Zhao et al., “VL-CheckList: Evaluating Pre-trained Vision-Language Models with Objects, Attributes and Relations.” arXiv, Jun. 22, 2023. doi: 10.48550/arXiv.2207.00221.
VL-CheckListでは、画像のキャプションに登場する名詞や形容詞を適当に入替えても、正しく理解できているなら入れ替え後のほうがスコアが少ないべき、という考え方に基づいたテストを行う。
安全性
AIの安全性を包括的にまとめた論文として、AI Risk Repository[^Slattery_et_al_2024]がある。AI Risk Repositoryでは、AIによるリスクを因果関係とドメインの2つの観点から分類している。 [^Slattery_et_al_2024]: AI Risk Repository
因果関係は次の3つに分類される。
- 人間由来か、AI由来か
- 意図的か、意図せず起きるか
- AI開発時の問題か、使用時の問題か
ドメインは次の7つに分類される。
- 差別
- プライバシー
- 誤った情報
- 悪意のある有用性
- AIへの不適切な依存
- 経済・環境
- AIシステムの限界
ハルシネーション
ハルシネーションの評価
ハルシネーションの低減
ハルシネーションの低減手法は、主にPrompt EngineeringとDeveloping Modelに分かれる。
Prompt Engineeringは、モデルの開発を伴わない手法全般を指す。プロンプト中に”Do not hallucinate”などの指示をするほか、Chain of Thought等が挙げられる。また、何度か出力を行ってから多数決を取るSelf-Check GPTや、複数のモデルで話し合わせるReConcileなどの手法がある。Developing Modelとしては、Fine Tuning時にRAGした知識を優先して答えるように訓練したり、知らないことを知らないと答えさせる手法がある。
分析
LLMの分析
Transformer言語モデルの分析には、主にProbingと注意パターンの分析の2つの種類がある。
Probing
-
A. Radford et al., “Learning Transferable Visual Models From Natural Language Supervision.” arXiv, Feb. 26, 2021. doi: 10.48550/arXiv.2103.00020. ↩
-
S. Goel, H. Bansal, S. Bhatia, R. A. Rossi, V. Vinay, and A. Grover, “CyCLIP: Cyclic Contrastive Language-Image Pretraining.” arXiv, Oct. 26, 2022. doi: 10.48550/arXiv.2205.14459. ↩ ↩2