til
プログラミング言語論 (programming language theory)
ページ構成にあたって次の情報源を参考にした。
- コンピュータシステムの理論と実装
- 最新コンパイラ構成技法
- 型システム入門 −プログラミング言語と型の理論
- Programming Language Design and Implementation
- Concept of Programming Languages
- Foundations of Programming Languages
- プログラミング言語論
- Claude🔐
プログラミング言語の歴史
コンパイラ
広義のコンパイラは、ソース言語で書かれたプログラムをターゲット言語のプログラムに変換するプログラムである。例えばC言語のプログラムは、GCCというコンパイラによって機械語に変換される。機械語はISAによって異なるので、コンパイラはオプションなどで対象のアーキテクチャを指定することができる。GCCの例は次の通り。
gcc -march=rv64gc example.c -o example
TypeScriptをJavaScriptに変換するような、ターゲット言語が機械語ではないコンパイルもある。これは狭義のコンパイルと区別するために、トランスパイルとも呼ばれる。
字句解析 (lexical analysis)
コンパイラの構文解析は、トークナイザ(tokenizer)とパーサー(parser)の2つのモジュールに分けられる。
構文解析
トークンの集合をツリー構造の命令として扱うためには、トークンの集合をいったん文法的に解釈すると良い。英語を日本語に翻訳する時に、SVOの品詞を当てはめるイメージである。
トークンを文法的に解析した結果を解析木という。解析木は、文脈自由文法の生成規則の文字をノードとして持つ木である。変数(非終端記号)が中間ノードであり、終端記号が葉である。
文法仕様が純粋な文脈自由文法による場合、入力トークン数をNとして計算量が$O(N^3)$に達する。そこで、文法仕様を文脈自由文法に制約を加えたLL(k)文法やLR(k)文法で書き直して高速化することが考えられる。構文解析法について次の表にまとめた。
| 構文解析法 | サポートする文法 | 計算量 | 戦略 | 特徴 |
|---|---|---|---|---|
| CYK法 | 文脈自由文法 | O(N^3) | 動的計画法 | チョムスキー標準形に変換が必要 |
| Earley法 | 文脈自由文法 | O(N^3) | トップダウン | 文法変換不要 |
| LL(k)法 | LL(k)文法 | O(N) | トップダウン | 再帰下降構文解析に適している |
| LR(k)法 | LR(k)文法 | O(N) | ボトムアップ | シフト還元法を使用 |
与えられたトークンの集合を、1つの変数から2つの変数が生成される規則に則った二分木として解釈し、規則を満たす組合せを探索するアルゴリズムをCYK法という。名前は人名に因む。動的計画法で実装できる。CYK法では、1変数(非終端記号)が2つの非終端記号または1つの葉(終端記号)を生成する制約に則った生成規則を必要とし、これをチョムスキー標準形という。
再帰下降構文解析(recursive descent parsing)では、パーサを再帰的なメソッドで構成する。例えばparseWhileStatement()はwhileトークンを解析し、残りのトークンを次のメソッドに渡す、という流れでパースできる。
文脈自由文法およびその部分集合について、次の表にまとめた。
| 文法 | サポートする言語 |
|---|---|
| 文脈自由文法 | 文脈自由言語 |
| LL文法 | LL言語 |
| LR文法 | LR言語 |
抽象構文
解析木では、木の中間ノードが変数(非終端記号)であった。しかし、実際の機械語には非終端記号は関係ない。そこで、中間ノードを演算子や制御構造によって置き換えて木を再構成する。この木を抽象構文木 (AST, abstract syntax tree)という。
意味解析
中間表現 (IR, intermediate representation)
機械語はIAによって異なる。ここで、ターミナルから実行するアプリケーションの開発者を考える(Webアプリはブラウザ上で動くため、すでにプラットフォーム非依存であり例えとして分かりづらい)。開発者がアプリケーションを公開するにあたって、IntelやAMDな複数のプラットフォームごとにコンパイルするのは大変である。そこで、もしプラットフォーム非依存の抽象化された機械語があれば、利用者がそれを機械語に通訳しながら利用することで、問題を解決できる。少し違うが、AWSのAPIを呼ぶプログラムの代わりにTerraformを使うようなものである。このようなプラットフォーム非依存の表現を中間表現といい、中間表現を機械語に通訳するプログラムを仮想マシン(VM)という。VMは、メモリ管理やスレッド管理などのプラットフォーム依存の処理を引き受けることもある。コンパイラにおいて、中間表現にコンパイルするまでをフロントエンド、中間表現から機械語をバックエンドと呼ぶ。
VMには、次のような種類がある。なお、厳密にはLLVMはVMではなくコンパイラのバックエンドだが、IRからコード生成を行うプログラムとしてまとめて表にした。
| VM/Compiler | IR | Source Language | Note |
|---|---|---|---|
| JVM | Java Bytecode | Java, Kotlin, Scala, Groovy, Clojure | 強力な最適化とGC |
| .NET CLR | CIL | C#, F#, Visual Basic .NET | Microsoftが開発 |
| GraalVM | Truffle AST, Graal IR | Java, JavaScript | Oracleが開発 |
| LLVM | LLVM IR | C, C++, Rust, Swift, Objective-C | コンパイラ基盤 |
| V8, Wasmer, etc… | WebAssembly bytecode | C, C++, Rust, AssemblyScript | ブラウザ内で動作 |
最適化
コード生成
構文木から機械語やVMコードへの変換を考える。機械語やVMコードは、基本的に動詞と目的語からなる。重要なのはその語順である。数式やプログラムを記述する方法として、次の3つが挙げられる。
- 前置記法 (ポーランド記法, PN, Polish notation)
- 中置記法 (infix notation, IN)
- 後置記法 (逆ポーランド記法, RPN, reverse Polish notation)
機械語やVMコードでは後置記法を基に拡張した形式を用いられることが多い。
コンパイル戦略
プログラムの実行にあたって、ソース言語を予め機械語に翻訳し、実行可能なバイナリファイルを生成することをAOTコンパイルという。一方で、プログラムの実行時にコンパイルする方式をJITコンパイルという。JITコンパイルの例としては、Rubyにおいて高速化を目的として有効化されるYJITや、JavaScriptの高速化のためにブラウザに搭載されたJITコンパイラ等がある。また、機械語へのコンパイラを用いずに、プログラムからVMコードを生成し、実行時にはVMがVMコードに対応する機械語に通訳して実行する戦略もあり、インタプリタ型と呼ばれる。いくつかの言語について、中間コード・機械語のそれぞれの観点から、コンパイル戦略をまとめた。
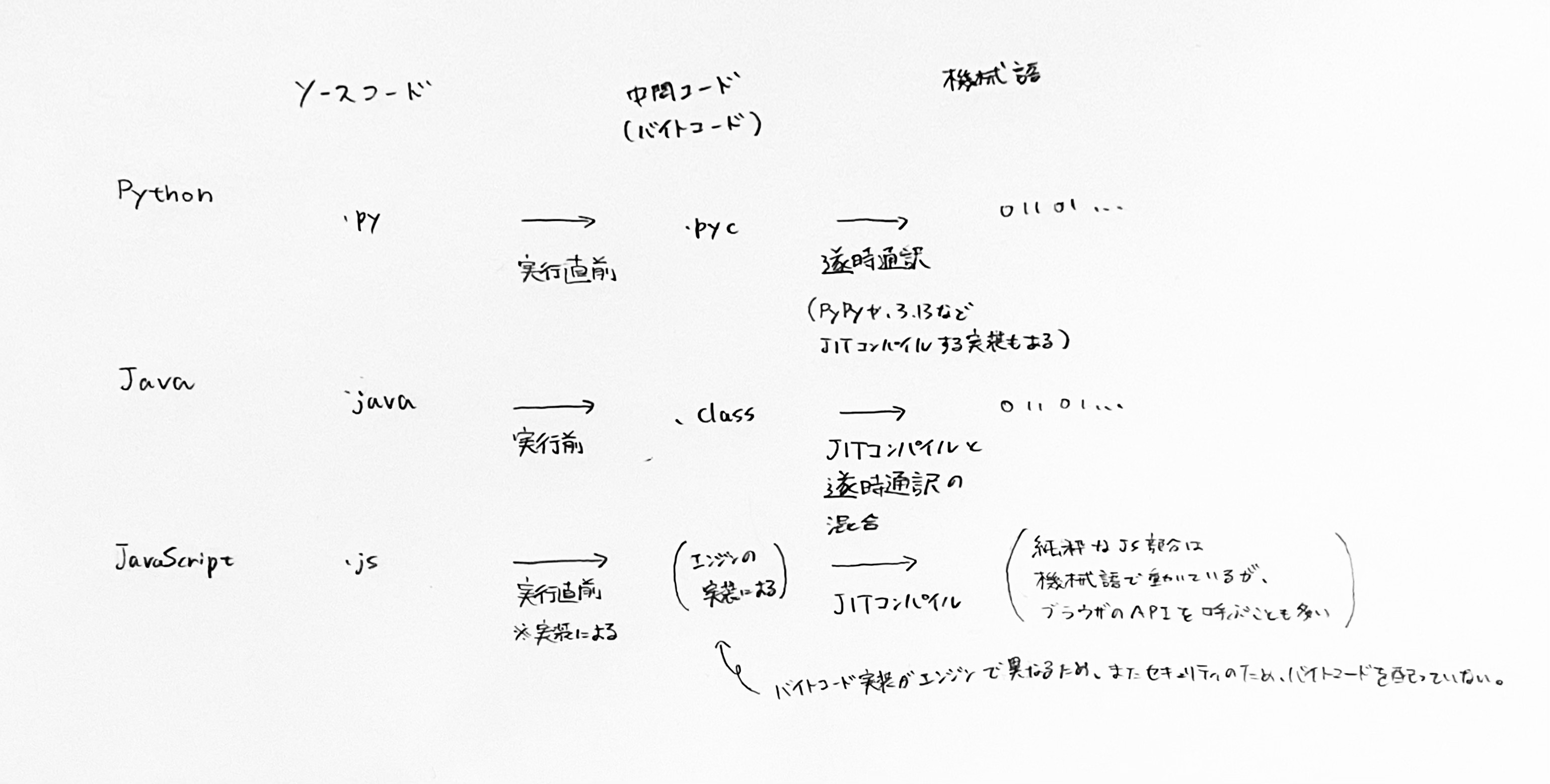
設計と実装
構文 (syntax)
メモリ管理 (memory management)
GC (garbage collect) は、プログラムが動的に割り当てたメモリのうち、もはや使用されていないメモリを自動的に解放するメモリ管理手法である。プログラマがメモリの割り当てと解放を手動で管理する必要がなくなり、メモリリークなどのバグを防ぐことができる。
スコープ, 関数, パラメータ渡し (scopes, functions and parameter passing)
関数において、関数定義において引数を受け取る変数と、呼び出し時に渡される値を、それぞれ仮引数(formal parameter)、実引数(actual parameter)と呼んで区別する。引数を渡す際、実引数を仮引数にコピーする方法を値渡しといい、引数の参照を渡す方法を参照渡しという。しかし、Pythonのような、再代入によってメモリアドレスに格納されたオブジェクトではなくメモリアドレスそのものを書き換える言語でこの分類を当てはめるとややこしいことになるので、その場合は正確にメモリアドレスの値を渡している、と言ったほうが無難である。
変数に代入したり、配列に格納したりできるオブジェクトを第一級オブジェクトという。数値や文字列は普通第一級オブジェクトである。関数や型が第一級オブジェクトであるかは、プログラミング言語によって異なる。関数が第一級オブジェクトである場合は、他の関数(関数ファクトリ)の内側で関数の生成ができるため、関数ファクトリ内の変数を参照し続ける関数を生成できる。この機能をクロージャ(閉包, closure)という。関数に状態を持たせたい、しかしクラスを定義するほどではないし、ジェネレータがサポートされていない、といった場合に便利なトリックである。
関数を再帰的に呼び出すとき、現在の実行位置をスタックに保存した上で、新たな関数をスタックにプッシュする。したがって、再帰的な呼び出しの回数が一定以上になるとスタックオーバーフローを起こす可能性がある。ここで、再帰的な呼び出しが関数の最後の行で行われている事を考える。最後の行で呼ばれているなら、新たな関数の実行完了後は呼び出し元の関数も完了するだけなので、スタックを保っておくのは勿体ない。そこで、同じスタックで実行するようにコンパイルしてしまうことを末尾再帰最適化という。
- カリー化: WIP
- モナド: WIP
制御構造 (control structures)
ループ
配列などの要素を順番に処理するにあたって、インデックスをインクリメントするのは冗長だが、配列をコピーしてpop()させるのはメモリの使用量が多い。そこで、現在が何周目かの状態を持ったオブジェクトを生成し、配列の要素の取り出しを任せよう、という発想で使うのがイテレータである。Pythonにおいては、マジックメソッドである__iter__を実装したクラスをイテラブルという。
また、配列の要素の取り出しが自分でカスタムできるなら、そもそも本当に配列を参照する必要がない。例として、次の2つのコードは同じ挙動を示す。
class OneTwoThree:
def __init__(self):
self.index = 0
def __iter__(self):
return self
def __next__(self):
self.index += 1
if self.index <= 3:
return self.index
else:
raise StopIteration
n_list = [1, 2, 3]
for n in n_list:
print(n)
one_two_three = OneTwoThree()
for n in one_two_three:
print(n)
配列から値を取り出すような、イテレーション毎の処理がインデックス以外は同じであるケースでは、イテレータが適している。一方で、「初回のループのみ初期化処理を行う」「内部状態がインデックスからは予測不能である」ようなケースでは、直感的な処理を状態と分岐処理に分けて書く必要があり、やや儀礼的になる。そこで、どこまで実行したかを記録し、次回呼び出す際には続きから実行できるジェネレータがあり、Pythonではyield演算子が相当する。
def one_two_three():
yield 1
yield 2
yield 3
型 (types)
- 型推論: WIP
モジュール化 (modularization)
パラダイム
オブジェクト指向プログラミング (OOP, object oriented programming)
関数の返り値でthisを返すことをfluent interfaceと呼び、メソッドチェーンによる簡潔な記述が可能になる。
関数型プログラミング (functional programming)
入力に対して出力が常に一定であること(参照透過性)を志向している言語を関数型プログラミング言語という傾向にあるようだ。データの流れが単純であり、そのことから単体テストが書きやすい(状態をモックしなくて良い)といったメリットがある。
論理プログラミング (logical programming)
複雑な主張が正しいかどうかを論理的に判断したいことがある。例えば、「顧客がプラチナ会員であり、かつ年間購入額が1万ドルを超えている場合には10%の割引を適用する」という主張があったとする。これに対して、手続き的に分岐を書いて判定するのではなく、事実とルールを羅列することで、その論理関係は自動で組み立てて欲しい、という動機がある。そのようなエンジンをルールエンジンという。そのような言語を論理型言語といい、代表例にPrologがある。
並行 / 並列 / 非同期プログラミング (concurrent / parallel / asynchronous programming)
システムがIO処理を行うとき、待ち時間にCPUで処理を行うことで処理性能を引き上げられる。そのための手段として自然に思いつくのがマルチスレッドだが、並行数が予め分かっているのであれば、もっと簡単な書き方が考えられる。即ち、並行処理は処理状態をオブジェクトとして返し、かつ同期的な文法を用いることである。このように、実行途中であっても処理を呼び出し元に返し、非同期で並行して処理を進める関数をコルーチンという。JavaScriptのasync/awaitはコルーチンである。
ドメイン固有言語 (DSL, domain specific language)
Foreign function interface (FFI)
FFIとは異なるプログラミング言語によって書かれたモジュールを呼び出すための仕組みを言う。例えばPythonにはctypesライブラリが存在し、C/C++で書かれた共有オブジェクトライブラリを読み込んでメソッド等の実行を可能にする。元々C/C++向けに書かれたコードをctypesで呼び出す場合は、データ型の変換等はctypesが担う。しかし、C/C++でPython向けのライブラリを実装する場合は、C/C++からPythonのメモリにアクセスする必要がある。そのような場合には、<Python.h>を用いるとよく、これもFFIと言える。
Uncategorized
- パターンマッチング
- 遅延評価
- 継続渡しスタイル